Comprendre les Transformers dans l’IA Générative¶
Quand on parle d’IA aujourd’hui, les Transformers reviennent souvent dans la conversation. Pourquoi ? Parce qu’ils ont révolutionné la façon dont on traite le texte. Avec leur mécanisme d’attention, ils sont capables d’aller vite, de traiter les mots dans leur contexte et surtout de produire des résultats impressionnants dans des domaines comme la traduction, la génération de texte, et bien plus encore.
Dans cet article, on va décortiquer les architectures principales des Transformers : l’Encodeur-Décodeur, l’Autoregressif et quelques variantes importantes. Alors, installe-toi bien, on plonge dans le vif du sujet. 😉
I. Architecture Encodeur-Décodeur¶
L’Encodeur-Décodeur, c’est l’architecture de base qui a marqué l’arrivée des Transformers dans le traitement automatique du langage (NLP). Tu la retrouves dans des modèles comme T5 ou encore dans l'article fondateur Attention is All You Need.
Tout repose sur deux couches complémentaires (un encodeur et un decodeur). Si vous êtes déjà familiers au deep learning alors pensez à auto-encodeurs , c'est plus simple.
- Encodeur : Son rôle, c’est de lire le texte d’entrée et d’en comprendre le contexte. Pour cela, chaque mot passe par une couche d’attention (qu’on appelle self-attention), qui permet au modèle de se concentrer sur les parties importantes de la phrase. Ensuite, les résultats traversent un réseau dense (feed-forward) pour produire des représentations riches du texte.
- Décodeur : Là, c’est un peu différent. En plus de la couche self-attention, il y a une couche spéciale appelée attention encodeur-décodeur. Cette dernière aide le décodeur à se concentrer sur les bonnes parties du texte d’entrée pendant qu’il génère les mots de sortie.
Voici un schéma pour bien visualiser tout ça :
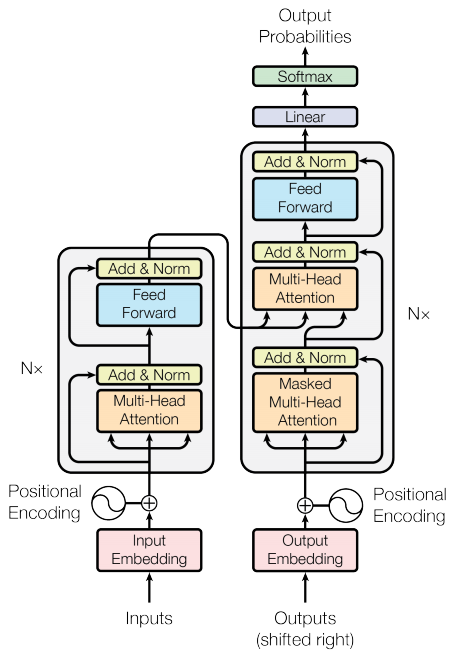
Un point à noter : Les blocs de l’encodeur et du décodeur sont souvent répétés plusieurs fois (N fois). Par exemple, avec N = 6, tu as 6 encodeurs et 6 décodeurs empilés.
En résumé, l’encodeur transforme le texte d’entrée en une représentation vectorielle compréhensible pour le modèle, et le décodeur utilise ces vecteurs pour produire le texte final. C’est comme ça qu’un modèle comme T5 arrive à traduire ou à résumer des phrases complexes.
II. Architecture Autoregressive : Le cerveau derrière GPT¶
Quand on parle de génération de texte, les modèles autoregressifs comme GPT sont les stars du moment. Contrairement à l’Encodeur-Décodeur, ici, pas d’encodeur : tout repose sur un décodeur.
Fonctionnement de GPT¶
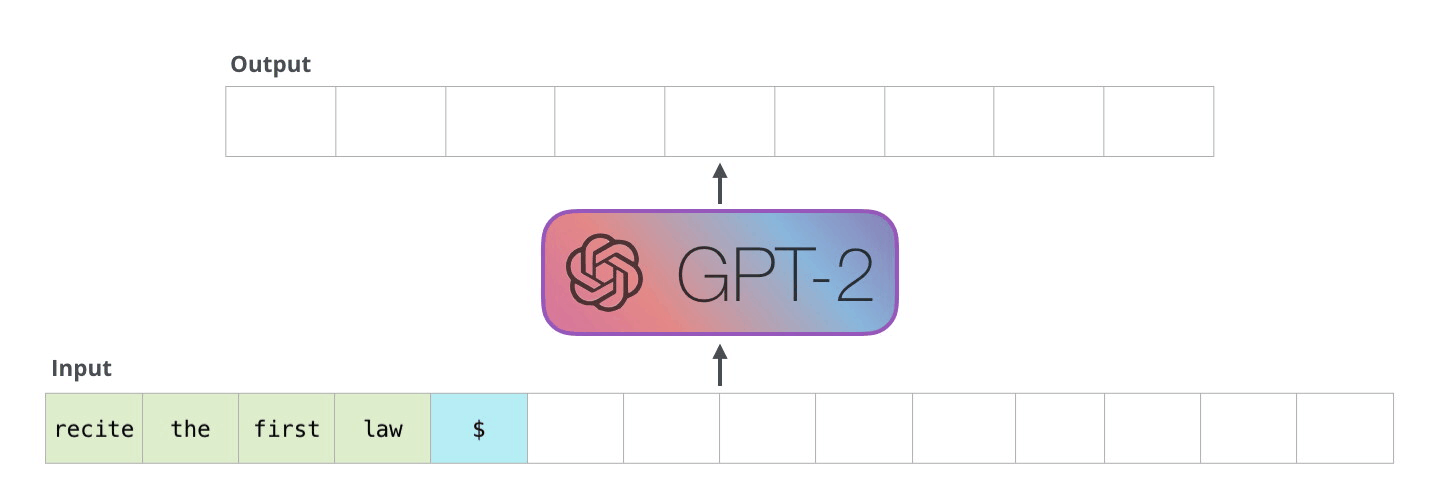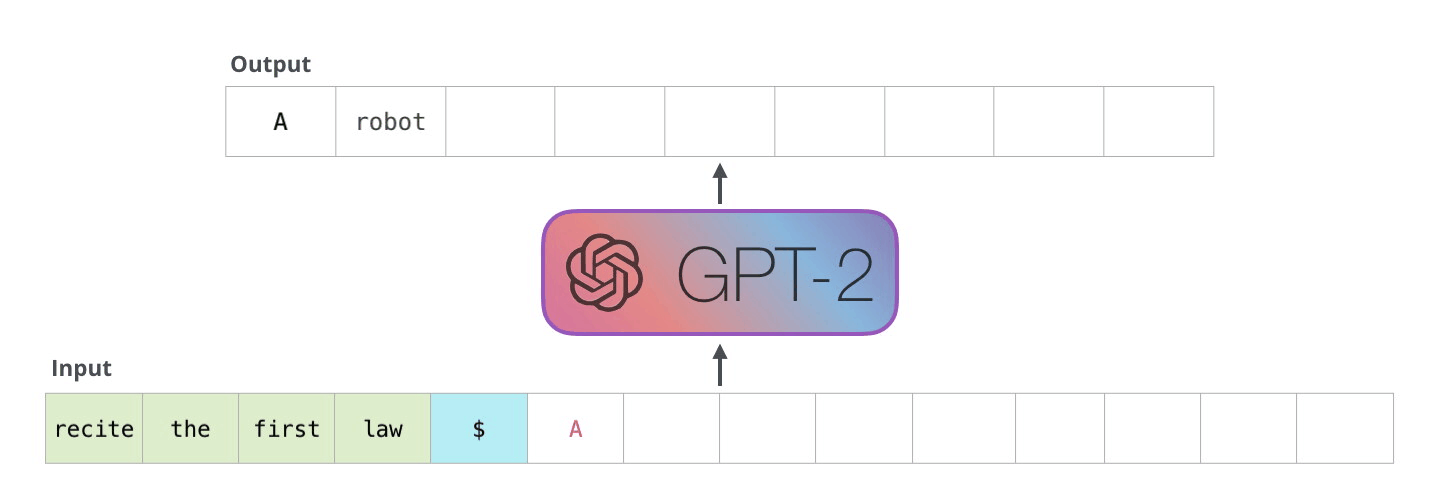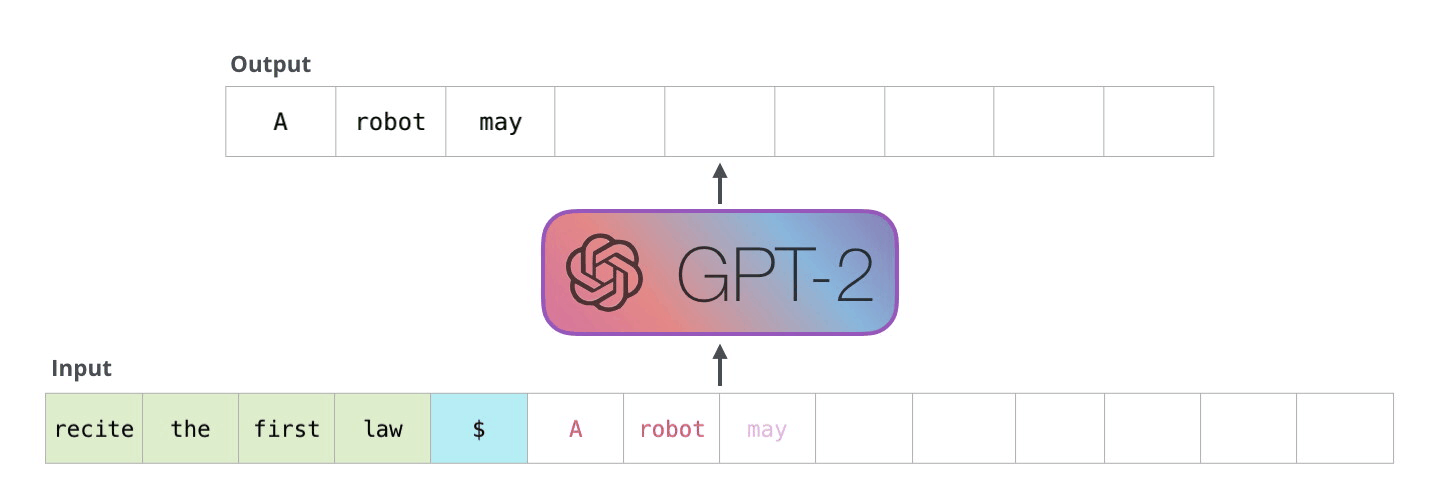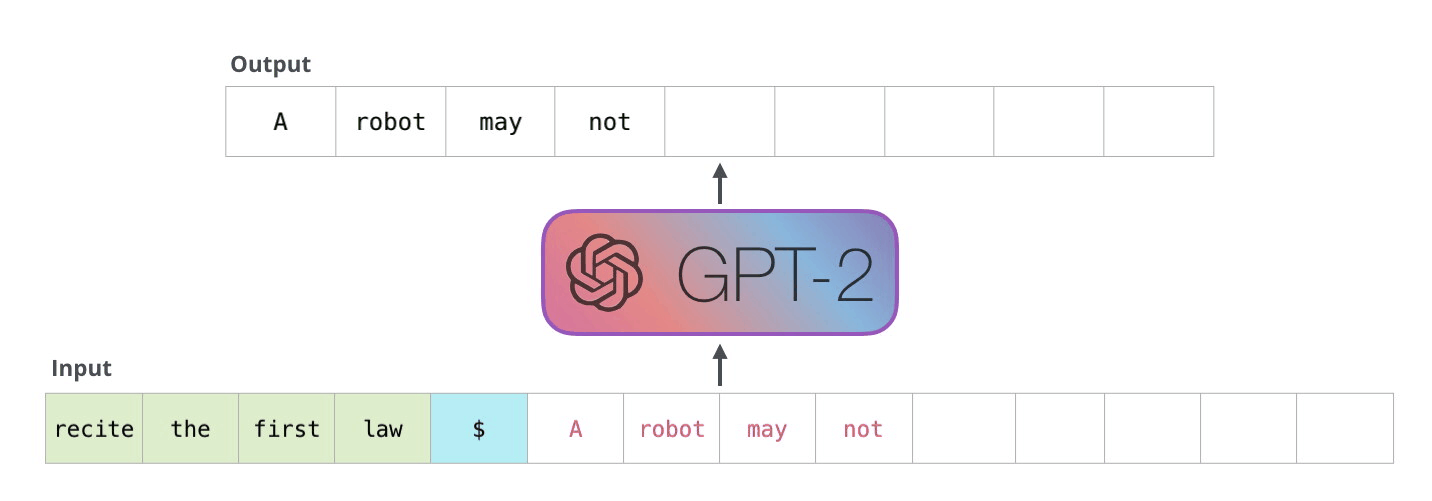
Le principe est simple mais puissant : le modèle génère un mot à la fois, en se basant sur les mots précédents. Chaque mot produit est ajouté à l’entrée pour prédire le suivant. Ce processus, qu’on appelle autoregression, permet au modèle de produire des textes fluides et cohérents.
Un exemple concret : si tu demandes à GPT-2 de citer la première loi de la robotique, il pourrait te répondre :
"Un robot ne peut porter atteinte à un être humain ni, en restant passif, permettre qu’un humain subisse un dommage."
Ce schéma illustre bien le processus autoregressif :
Modèles similaires¶
En dehors de GPT, on retrouve d’autres modèles autoregressifs comme Transformer-XL et XLNet, qui améliorent encore plus la compréhension du contexte.
III. Variantes et extensions des Transformers¶
Les Transformers ne s’arrêtent pas là. Certains modèles apportent des innovations spécifiques : - BERT : Ici, pas d’autoregression. BERT utilise une approche bidirectionnelle, qui lui permet de comprendre le contexte avant et après chaque mot. - XLNet : Ce modèle combine les forces des deux mondes (autoregression et bidirectionnalité) pour mieux capturer le sens des phrases.
Les Transformers ne se limitent pas au traitement du texte. Aujourd’hui, ils sont aussi utilisés dans la vision (ex. Vision Transformers), la reconnaissance vocale, et même dans l’apprentissage par renforcement.
Conclusion¶
Les Transformers, c’est vraiment l’outil indispensable en NLP moderne. Que ce soit pour traduire, résumer ou générer du texte, leur impact est énorme. Si tu veux approfondir, voici quelques ressources que je te recommande vivement :
- L’article fondateur : Attention is All You Need
- Guide sur les Transformers : Hugging Face
- Blog sur GPT et XLNet : Loick Bourdois